【新唐人北京時間2023年11月17日訊】近日,網友實測了ChatGPT、文心一言看圖說話的能力,結論是:一個可以稱智商,一個是智障。
11月15日,微信公眾號「Howie和小能熊」發文說,受網友啟發,決定讓ChatGPT和各個大模型一起來看圖說話,橫向對比下大模型的能力。
文章說,選取的圖片不是隨手拍照,而是漫畫。漫畫類圖片是人類藝術家的創造性表達,經常有一些幽默、諷刺等微妙之意蘊含其中,需要一些理解能力才能解讀。所以,測試的不只是「視力」,更是「智力」。
他用幾幅圖片,實測了美國ChatGPT和中國大陸百度開發的「文心一言」的看圖說話能力。結果如下:
第一張圖是《New Yorker》雜誌最新一期封面:

作者說,ChatGPT的回答「內容描述準確無錯誤,理解到位且無錯誤」。

而文心一言的回答「充滿了錯誤和幻覺,胡說八道的實例。你家小孩寫看圖作文寫成這樣,也就是0分了」。

第二幅圖,名爲「人類沉迷,機器學習」(Humans are hooked, machines are learning)。

作者評價,ChatGPT的答案「描述上有錯,把長椅說成了課桌,理解上,GPT強調沉迷手機的人類忽視了外部環境和培養成長和創造力的活動,沉浸於數字世界。很棒!」

而文心一言的回答「描述上胡言亂語,理解上亂七八糟。橫批:什麼玩意」。
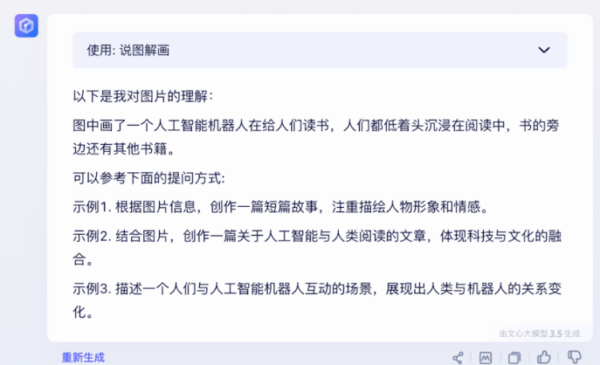
第三張圖片,是Peanuts漫畫「Born to Sleep」(天生喜歡睡覺)。

作者評價說,ChatGPT「描述ok,還提供了人物的作者信息,可見世界知識很全。理解上,還腦補了snoopy的內心活動,不錯!」

而文心一言「描述上大量錯誤,胡說八道。理解膚淺」。

作者還測試了其它實例,最後表示,自己之前認為兩者存在幾倍差距(1倍以上、10倍以下),但是現在發現,用數量差距、百分比、倍數來評價這些結果差異是不合適的。因為本質上不是數量差距,而是性質差距。無論是差2倍還是5倍,實際上都是不及格,都是不能用,對真實用戶的真實使用場景沒區別,都沒意義。
所以,更準確的說法:這是 「能用」和「不能用」的差距。所謂「能用」,就是能用來取代你的部分任務,可以整合到你的工作流;而不能用,就是不能啊。
作者說,一個「不能用」的AI,看起來一本正經,甚至「不明覺厲」,但是,與真正的智能,還是有一字之別。
(責任編輯:李酈)